
Grid computing, een afstammeling van de cloud en grote broer van gedistribueerd computergebruik.
Beschouw grid computing als het kruispunt van twee kernsystemen van organisaties: cloud computing en openbare voorzieningen zoals elektriciteit. Op dit kruispunt stelt grid computing u in staat om computationele bronnen aan te boren met beveiligde webgateway, gecentraliseerd en niet. Net zoals je de nabijgelegen energielijnen zou aanboren voor enkele van die glorieuze elektronen waarop we vertrouwen.
Een modern elektriciteitsnet heeft veel inputbronnen. Energiecentrales dragen bijvoorbeeld veel bij aan het elektriciteitsnet, maar ontluikende technologieën, zoals zonnepanelen en windmolens, democratiseren de elektriciteitsproductie.
Onafhankelijke en ambachtelijke energieproducenten kunnen bijdragen aan het elektriciteitsnet en een vergoeding ontvangen. In sommige gevallen is dit overtollige energie.
Boeren hebben bijvoorbeeld zonnepanelen om lokaal goedkopere elektriciteit op te wekken. De boer kan echter geen ongebruikte elektronen opslaan voor toekomstig gebruik, dus kan hij ervoor kiezen om die overtollige energie terug te leiden naar het energienet, waar anderen het kunnen gebruiken. De verspilde elektronen van de een zijn de volledig opgeladen Tesla van de ander.
Grid computing lijkt veel op het elektriciteitsnet. Bijdragers, groot en klein, kunnen bijdragen aan het raster. Gebruikers kunnen gebruikmaken van het computernetwerk en toegang krijgen tot diensten onafhankelijk van de bijdrager.
De Cloud, Grid en Distributed Computing
Om beter te begrijpen wat grid computing is en wat de genuanceerde verschillen zijn met gedistribueerde computing, zal het gemakkelijker zijn om eerst de barrière en beperkingen te begrijpen die grid computing kan overwinnen. Met andere woorden, als we de problemen zien die grid computing kunnen oplossen, zullen we beter begrijpen wat grid computing is.
De beperkingen van cloud computing zijn waar het raster schittert
Grid computing is een subset of uitbreiding van cloud computing. Kortom, cloud computing is het uitbesteden van rekenfuncties. Met een veelgebruikte cloudservice, zoals opslag van cloudgegevens van Google Drive of Dropbox, kan een klant zijn gegevens bij die bedrijven opslaan.
Iemand die gegevensopslag in de cloud wil gebruiken, kiest tussen providers als Google Drive, Dropbox en iCloud. Het bedrijf waarmee ze samenwerken, zou dan hun leverancier van cloudopslag zijn. Klantondersteuning, probleemoplossing, facturering, netwerkinfrastructuur en alle aspecten van het leveren van de cloudservice aan de klant komen dan rechtstreeks en uitsluitend van het bedrijf dat ze kiezen.
Vrij eenvoudig, toch? Eén klant, één provider. We zoeken echter naar de beperkingen van cloud computing. Waar schieten de voordelen van cloud computing tekort en is er ruimte voor andere organisatiestructuren zoals grid computing?
Veelvoorkomende kritiek op cloud computing:
- Gebruikersbronnen worden toegewezen aan een enkel symmetrisch multiprocessing (SMP) -systeem.
- Ongebruikte computerbronnen blijven inactief en worden vastgehouden aan een enkele taak totdat deze is voltooid.
- Relatief beperkte schaalbaarheid.
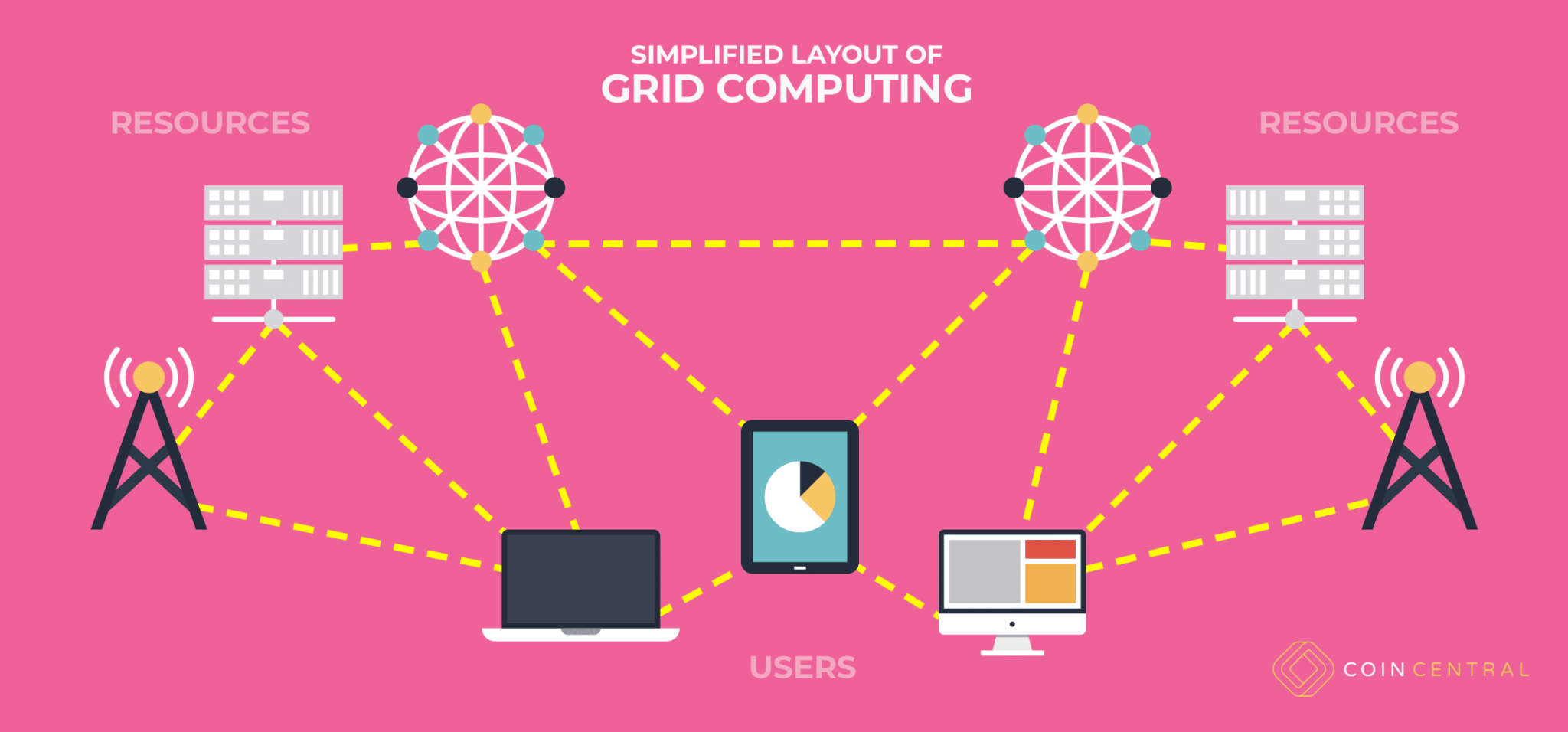
Evoluerende cloudbeperkingen met Grid Computing
Rekening houdend met de parallellen die grid computing heeft met een openbaar elektriciteitsnet, kan dit type computationele organisatie enkele van de veel voorkomende kritiek op cloud computing verlichten..
Laten we elk van deze beweringen eens bekijken en onderzoeken hoe een rastersysteem voor een gebruiker gunstiger zou kunnen zijn dan een traditionele cloudservice.
Cloudbeperking # 1: Gebruikersbronnen worden toegewezen aan een enkel symmetrisch multiprocessing (SMP) -systeem.
Ik zal een heel eenvoudig voorbeeld gebruiken om dit pijnpunt te laten zien. Er is een neurale wetenschapper die op zoek is naar twee datasets (set A en set B). Deze datasets zijn enorm en ze zal de taak moeten uitbesteden aan een cloudservice.
De cloudservice heeft geen probleem met het draaien van deze datasets en huurt er graag één machine van om haar datasets te verwerken. Onthoud dat haar datasets exclusief voor elkaar zijn en afzonderlijk moeten worden verwerkt.
Dit betekent dat de enkele SMP-machine die ze heeft gehuurd, Set A draait, gevolgd door Set B. Haar enkele machine kan beide datasets niet tegelijkertijd verwerken.
Geen probleem, de cloudmachines die ze heeft gehuurd, zijn zwaar belast en scheuren elk in minder dan een paar uur door de enorme datasets. Het verwerken van de gegevens kost de wetenschapper minder tijd dan een volledige nachtrust.
Wat gebeurt er als ze dezelfde verwerking moet uitvoeren, maar voor 100 gegevenssets? Haar budget geeft haar nog steeds maar genoeg geld om toegang te krijgen tot één cloud SMP-machine. Als wetenschapper doet ze snel de wiskunde en ontdekt dat het bijna twee weken zal duren om al die gegevens te verwerken!
Netvoordeel: Dezelfde wetenschapper met twee datasets (set A en set B) zou in plaats daarvan een rasterdienst kunnen aanboren. In plaats van dat de wetenschapper een enkele SMP-machine huurt bij een cloudservice, zou ze toegang krijgen tot het computernetwerk en de benodigde rekenkracht huren.
De twee datasets worden tegelijkertijd verwerkt. Misschien door twee machines, elk toegewijd aan een van de datasets, of het kunnen duizenden machines zijn die elk de datasets fractioneel verwerken. De gegevens worden hoe dan ook parallel aan elkaar verwerkt. Wat voorheen zes uur duurde in twee batches, duurt nu drie uur in één batch.
Honderd datasets? In theorie zou dit nog steeds maar drie uur duren, aangezien elke dataset naast elkaar wordt verwerkt.
Cloudbeperking # 2: Ongebruikte computerbronnen blijven inactief en worden vastgehouden aan een enkele taak totdat deze is voltooid.
Voortbouwend op het bovenstaande voorbeeld van een neurale wetenschapper, verwerkte de clouddienst die ze verhuurde onafhankelijk haar datasets, de een na de ander.
Bij het verwerken van beide datasets merkte de wetenschapper dat haar gehuurde hardware slechts op 80 procent van de capaciteit werkt. De resterende 20 procent is niet genoeg om de tweede dataset te verwerken, maar wacht werkeloos op de volgende taak.
Netvoordeel: Door de commodificatie van verwerkingskracht kan een enkele taak op meerdere machines worden uitgevoerd. In het geval van de datasets van de wetenschapper zou een rastersysteem de gegevens kunnen verwerken in een reeks combinaties tussen machines.
De twee datasets worden bijvoorbeeld toegewezen aan twee machines in het raster, die elk 80 procent van de machine gebruiken waarop ze worden verwerkt. De resterende 20 procent zou niet werkeloos zitten, maar een andere gebruiker van het raster legt het vast. Dit gebruik van inactieve capaciteit is een belangrijk onderdeel van de sterke punten van grid computing.
Cloudbeperking # 3: Relatief beperkte schaalbaarheid
Het valt niet te ontkennen dat de mogelijkheden van cloud computing exponentieel groter zijn dan bij de meeste gelokaliseerde machines. De meerdere lagen naar de cloudstack hebben veel meer deelnemers aan het hele veld mogelijk gemaakt dan ooit tevoren.
Bovendien heeft cloud computing veel schaalvoordelen in vergelijking met zelfbeheer van dezelfde diensten. Dus om te zeggen dat cloud computing dat is ook beperkt in schaalbaarheid lijkt misschien een beetje paradoxaal.
In vergelijking met cloud computing is schaalvergroting op een grid echter nog beter haalbaar. Dit is gedeeltelijk te danken aan de modulariteit van gridcomputing naast het efficiëntere gebruik van inactieve bronnen.
Netvoordeel: Ongeacht of u eraan bijdraagt of er gebruik van maakt, het schalen van uw taak in een gridcomputersysteem kan net zo eenvoudig zijn als het installeren van een gridclient op extra machines.
In het geval van de neurale wetenschapper was ze in staat om haar behoeften te schalen van twee datasets naar 100 datasets in hetzelfde tijdsbestek, met hetzelfde budget.
Gedistribueerde computers of gridcomputers?
Beide! Ja soort van.
In gesprekken is het vrij gebruikelijk om raster en door elkaar gedistribueerd te gebruiken. In wezen verwijzen beide termen naar redelijk vergelijkbare concepten. Het zijn beide systemen voor het organiseren en netwerken van computationele bronnen.
Als u echter echt haren wilt splitsen, is grid computing de algemene verzameling gedistribueerde netwerken. Grid computing zelf is een gedistribueerd netwerk van gedistribueerde netwerken. Meta genoeg voor jou?
Wat is de volgende stap voor Grid Computing?
Dit was een zeer macro-begrip van grid computing. In feite is het een veelzijdig systeem voor het organiseren van een reeks dynamische en individuele onderdelen, om er het meeste uit te halen. Elk onderdeel van het computernetwerk is gelaagd met complexiteit en bruikbaarheid, vergelijkbaar met de verschillende onderdelen die nodig zijn in een openbaar elektriciteitsnet.
Net als bij een openbaar nut, is de manier waarop het werkt een beest op zich. De echte impact is echter de algehele toegankelijkheid. Omdat grid computing, net als een openbaar nut, steeds meer een plug-and-play-service wordt.
De volgende evolutie van grid computing zit waarschijnlijk in de blockchain. Grid computing is afhankelijk van het feit dat meerdere belanghebbenden elkaar vertrouwen. Projecten zoals Cosmos Network creëren al gedecentraliseerde grid-systemen die netwerkinteroperabiliteit bevorderen en de kracht van een grid computing-netwerk benutten.

